



A Systematic Approach to Processing Research Literature
A Notion implementation of the three-pass method

Epistemic Status: medium, implements popular methodology that I validated with veteran researchers, I have not received feedback on this particular concrete implementation
Epistemic Effort: medium, I started with the methodology, defined purpose, diagrammed the system, implemented with Notion, tested it with real-world use, made revisions
In my previous blog post, I introduce an effective methodology used by many researchers and practitioners (including myself) to streamline literature review. But what’s a methodology without a concrete system implementation?
In this follow-up post, I discuss the system design of my Research Processing System (RPS) which implements Keshav’s three-pass approach.1 The productivity stack I use is Notion (workflow management), Zotero (reference management), Highlights (notes in the margins), and Obsidian (PKM), but the RPS design I present can be applied to any stack. I also provide links to my Notion RPS template (free) and my LucidChart system diagram.
P.S. You should read the methodology first.
System Purpose
Before designing the system, it’s a best practice to first define the system purpose. According to design thinking frameworks, one should first identify points of friction in the user journey. In my predecessor post, I briefly mention four challenges of literature review:
Volume: There is a vast amount of literature.
Velocity: The rate of publications is high, making it difficult to keep up.
Verbosity: Papers tend to be wordy and contain a lot of information that is irrelevant to your needs.
Vernacular: The choice of words can make it challenging to read, as you may constantly need to look up unfamiliar terms or jargon.
Thus, the purpose of an RPS should be to mitigate these problems with better attention management, i.e. place guardrails to ensure you pay attention to the right information at the right times. In short, we want the RPS to make literature review more feasible, targeted, and streamlined.
Components of a Three-Pass Research Processing System
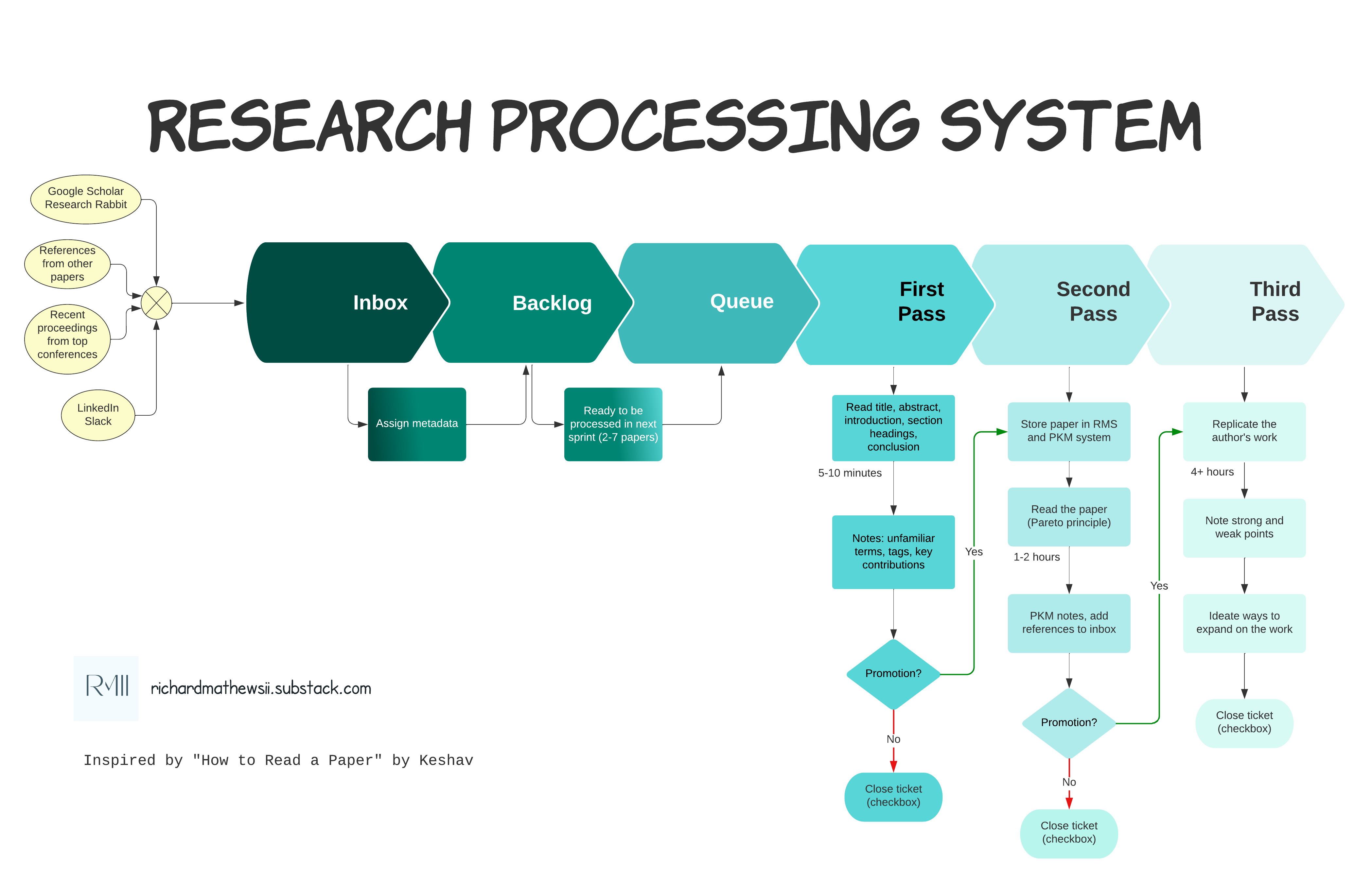
At this point, the three-pass approach is abstract. It’s time to make it concrete, and that means systemization. Using some basic systems design skills, I devised the following components for an RPS.
Quick Capture: First, you need a way of getting papers into your system, which means there needs to be a quick capture mechanism. This should be as low friction as possible, no more than a few seconds.
Inbox: You need a “first stop” for all incoming papers. This is an inbox. The only required metadata at this point is the title of the paper and a URL. Once the paper is in the system, I refer to it as a “ticket” or “record.”
Backlog: There might be some important metadata, like the topic of the paper (since you may be interested in multiple domains), that you want to query tickets by when deciding what to do a first pass on. Once a ticket is annotated with the required metadata, it moves to the backlog. Tip: make the requirements explicit… nothing goes in backlog without first meeting your metadata requirements.
Queue: The backlog will get fairly large over time, so you need some way of focusing on a batch of 2-7 papers to do a first pass sprint on. This is the purpose of the queue component. With a batch of papers in the queue, it’s time to begin Keshav’s three-pass approach.
Pass One: The first pass component is designed to handle the volume and velocity problems by reducing the incomprehensible space of papers into a manageable subset that you can process. Like a wheat threshing machine, it separates the wheat from the chaff. At this level, it’s all about speed. I’m talking no more than 10 minutes on a paper, ideally, it’s 5 minutes.
Pass Two: The second pass component is what I call a “Pareto dive”. It’s a parsimonious information extraction process using 80/20 analysis (Pareto principle) and is designed to solve the verbosity and vexing verbiage problems by reducing a highly academic description of information into a set of “highlights” and “margins” that explain the key ideas clearly. The takeaways should be stored as notes in your PKM system of choice.
Pass Three: The third component is a “deep dive”. This is a rarity considering the time and cognitive costs, but necessary if you are a practitioner seeking to implement the idea or if this paper is critical to your current line of research.
Repository: There also needs to be a “sink” or storage location for processed papers. This is where you search for papers you’ve already processed, so you need to consider important metadata to query on (e.g. topic, author, institution). You will also want a quick glimpse of what the paper is about. This is the repository component.
An Overview of My Research Processing System in Notion
I implemented a three-pass RPS in Notion with all of the components I described above, which is available on my productivity portfolio for free. It’s simple, intuitive, and incredibly powerful. Creating this system really flipped the switch on my ability to churn through literature. Let’s dig into it.

The system consists of a “Research Papers” database, 4 table views, and a Chrome-based quick capture plugin (see the template for instructions on setup).
The inputs to the system are sourced from paper references, academic search engines, network-based systems like ResearchRabbit, papers from proceedings of recent conferences, and social platforms like LinkedIn or Slack.
The Status Board includes the following:
Inbox: Landing destination for incoming research papers.
Backlog: Research papers that have been tagged with a topic. This allows you to filter by topic when you want to queue up a batch of papers from a particular area in your next first pass sprint.
Queue: Ready to be processed in the next first pass sprint (2-7 papers).
First Pass: Completed first pass. Only move a paper here when you completed a first pass.
Second Pass: Completed second pass. Only move a paper here when you completed a second pass.
Third Pass: Completed third pass. Only move a paper here when you completed a third pass.
The closed property is how you close a ticket… you’ve decided no more passes, we are done here.
The database itself offers 4 views:
Backlog: Storage of unprocessed papers that have been tagged… ready to be queued. This is where you explore new papers you want to process.
Status Board: Manage the workflow of processing research papers via Keshav’s method. Tickets should be closed once you have completed processing.
Repository: Storage of all processed papers, organized by how many passes you gave it.
Gallery: View all papers that have undergone at least one pass, with an AI-generated summary of your notes.
External Dependencies
I use a few other systems in my workflow.
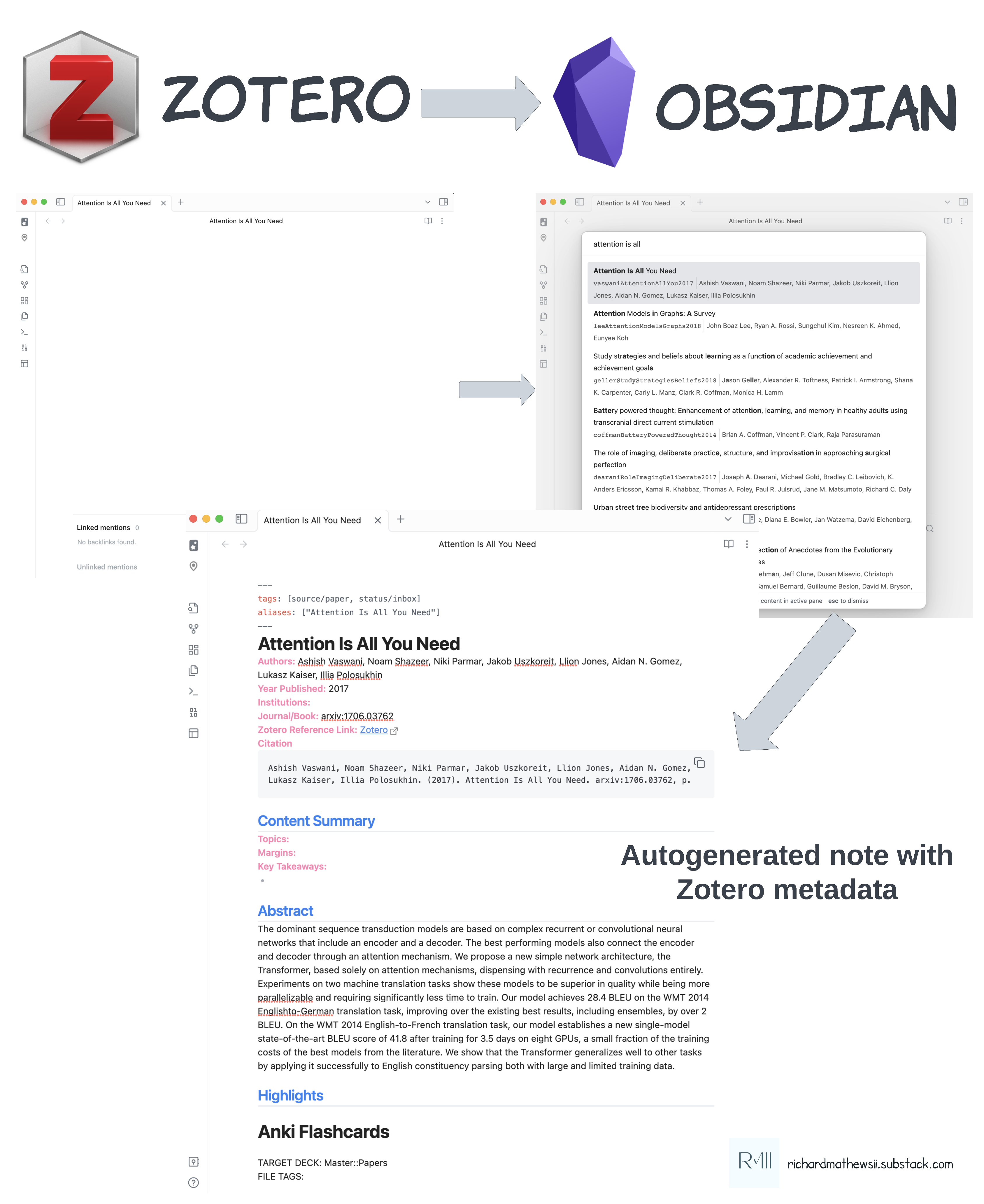
Reference Management System - Zotero
All I really use an RMS for is to organize my pdf files into subcollections and extract metadata for autogenerated citations. The main reason I use Zotero is because of the Zotero Obsidian plugin, which makes it easy to import my paper’s metadata into a structured format to my Obsidian notes.
Personal Knowledge Management - Obsidian
My PKM system is implemented in Obsidian. This is where I also store notes on papers I do a second pass on. Using the Zotero plugin, it’s easy to import templated content into my notes and cite papers in my notes.
PDF Annotator - Highlights
I use the Highlights app to take notes in the margins. This app captures highlights, and even pictures of tables or diagrams, with your own notes. I also like to export the PDF of my margins and store those in my Obsidian vault, titled “Margins - {Paper Title}”.
Walk-Through Using LLMs as an Example
First Pass
Let’s pretend I am a data scientist (easy to do since I am a data scientist), and I want to do a literature review with my new Notion RPS. There is a lot of hype around LLMs, so I am interested in exploring the literature in this area. I have collected a batch of the landmark papers in this domain and created a queue of papers to read.
Attention Is All You Need
Deep Contextualized Word Representations
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Language Models Are Few Shot Learners
It’s Saturday morning (when I usually do a first pass sprint). I wake up, take a walk, get some sunlight in my eyes, take a cold shower, and pop a caffeine pill. At this point, my brain is drenched in cortisol and I am wired in, ready to go.
I lock my phone in a vault, put some headphones on, blast brown noise, and open up my Notion system. There is my queue of papers. I pick the first one and move down from there. Each one, I time how long it takes, so I know I am not spending more time than I should. I copy and paste key contributions and findings (from the abstract and conclusion mostly), use Notion AI to clean it up, and then at the end, the Notion AI property automatically updates.
After reading each paper, I move it to the second pass bucket and decide whether to do a second pass. I aim for a 20% hit rate, but sometimes it's higher if the batch of papers I selected are all important. In this case, I promote "Attention is All You Need" for its transformer innovation and the GPT3 paper for its in-context learning innovation. I mark the papers I am done with as "Closed", and they disappear from the Status Board and appear in the repository view.
Second Pass
Rise and shine… it’s Sunday morning. Same procedure as Saturday… sunlight, cold shower, caffeine… it’s paper time.
I picked two papers to do a second pass on. I typically only do one, but sometimes two, and rarely three.
I open the first one, download the paper, store it in Zotero, and use the Obsidian Zotero plugin to import the metadata into a new note for that paper. At this point, a second pass means the paper has “earned” its place in my PKM graph.
I open the paper with Highlights and I do a second pass, highlighting important parts as I go, making comments in the margins. I try to find potential areas of improvement, how the technique might apply to problems I currently face, or how I might implement them.
Once finished, I export the margins to a PDF, store that in my PKM vault, link it to my paper note, and then add a few major highlights as quotes in the note. Then I extract key takeaways, write information in other notes related to the ideas, link notes to the paper, etc. I might also add some of the learnings to my SRS (Spaced Repetition System). This is all part of a process I call “PKM engineering” (more to come on that later posts).
Then I decide if this warrants a third pass (almost never does). Most likely, I just move it to the second pass bucket and close the ticket.
For a post-learning protocol, I like to do some NSDR (Yoga Nidra).
Conclusion
In this article, I discussed how you can implement Keshav’s three-pass approach to efficiently process research literature. I started by defining the purpose of a research processing system and identifying the challenges of literature review. Then, I presented the components of a three-pass RPS, which can be applied to any productivity stack. I also provided an overview of my personal implementation using Notion, Zotero, Obsidian, and Highlights. If you are interested in my Notion template, download it for free at this link.
References
Keshav, Srinivasan. (2007). How to Read a Paper.
AMAZING LOVE IT I HOPE I CAN IMPLEMENT THIS